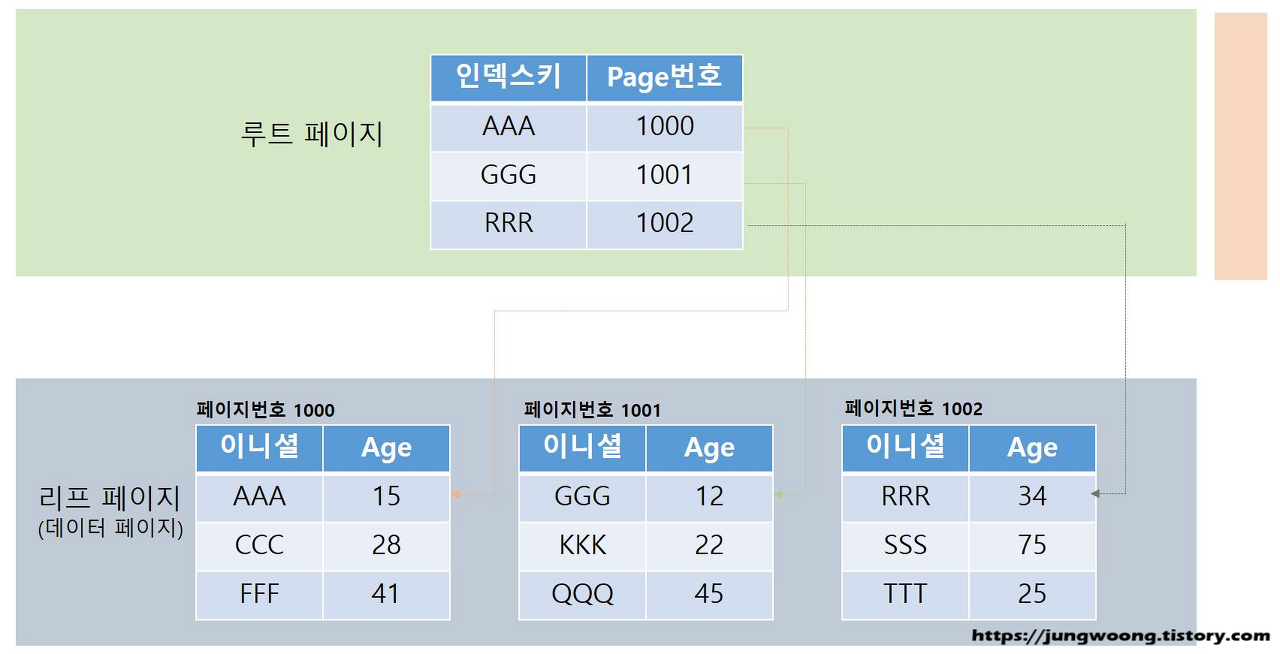
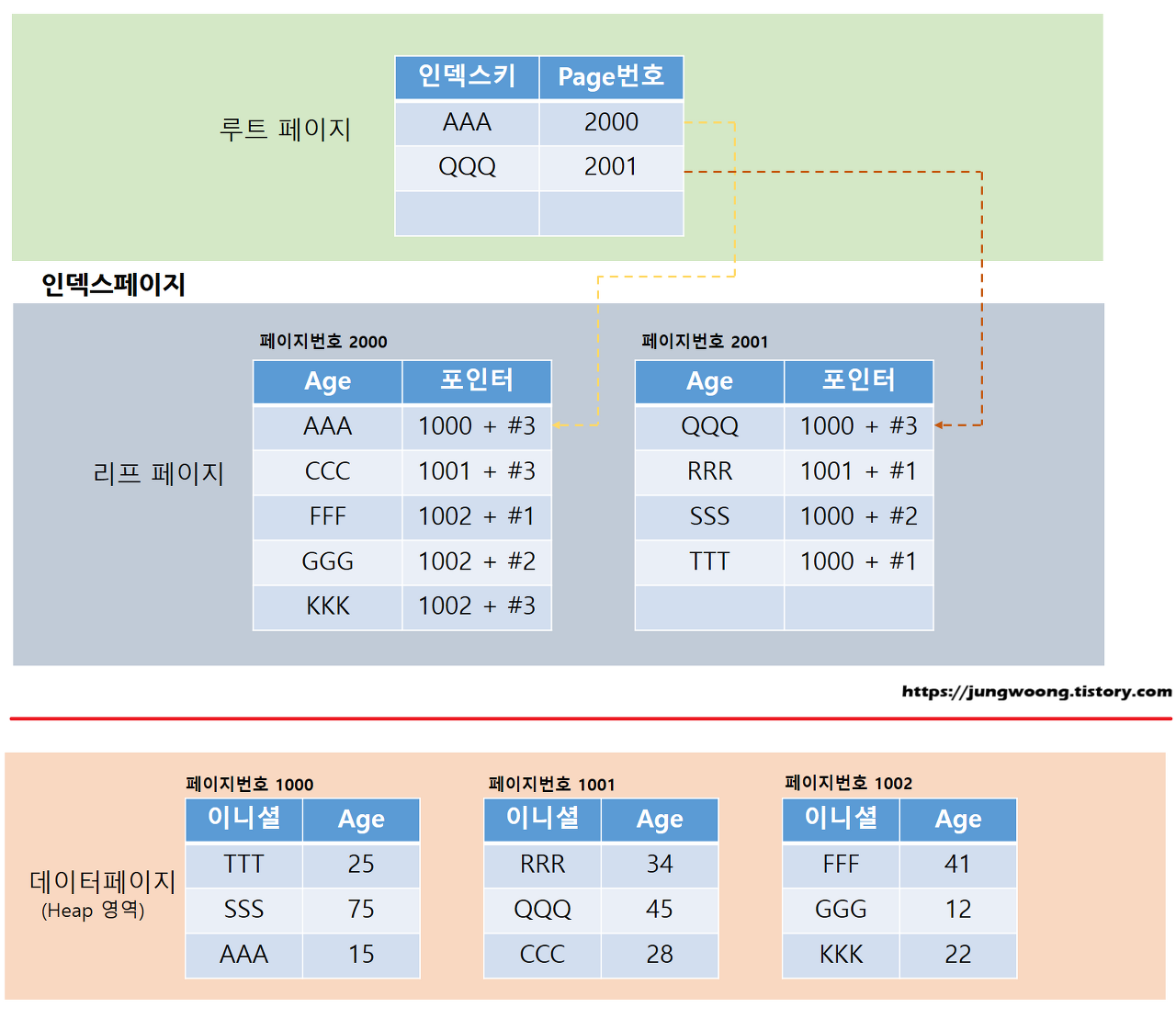
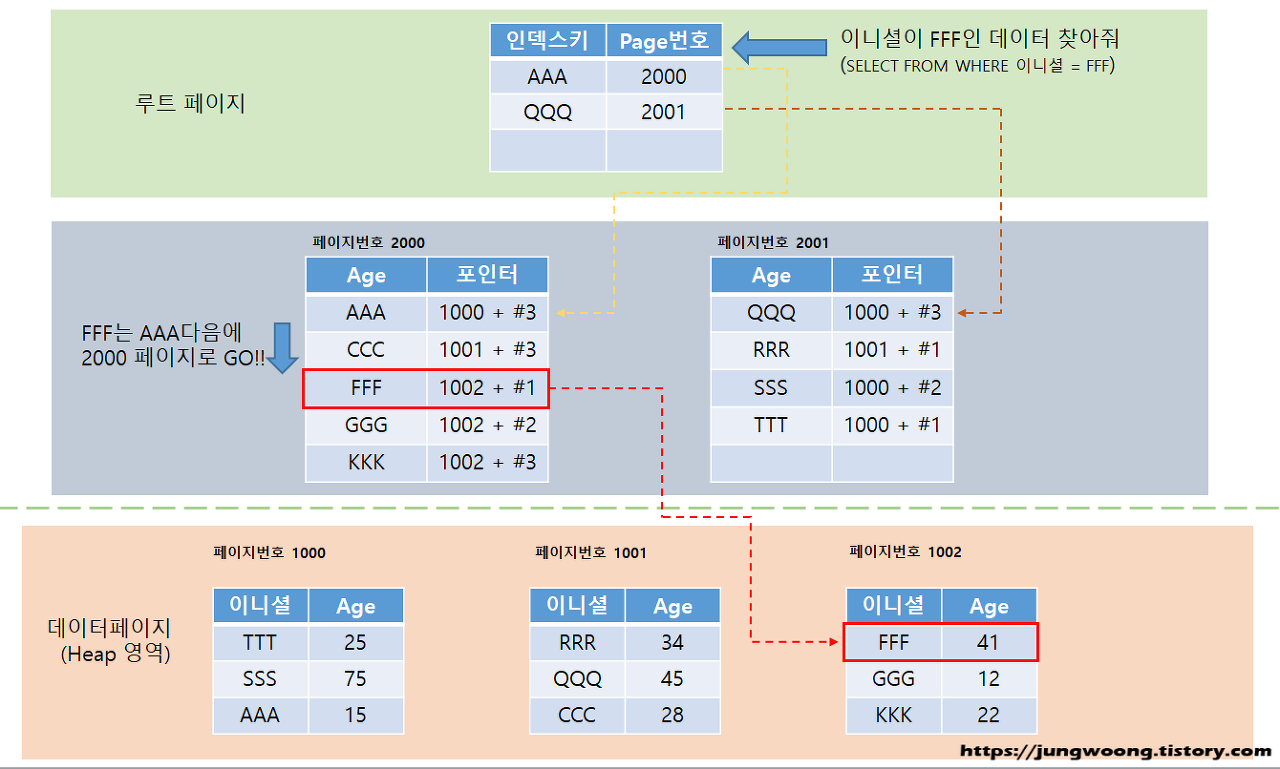
코드리뷰#
코드리뷰란, 한 명 또는 여러 명의 개발자가 본인이 만들지 않은 코드의 내용을 점검(examining)하고, 피드백을 주는 과정을 말한다.
여기에서 피드백이란 오타, 버그 가능 성, 개발 표준 등에 대한 의견이 될 수도 있고, 좋은 코드에 대한 긍정적인 피드백이 될 수도 있습니다. 코드리뷰의 핵심은 단순히 코딩 스타일을 일관되 게 유지하거나, 예상되는 문제를 일찍 파악하는 데에 그치지 않고 코드에 대한 책임이 그 코드를 만든 사람 혼자에게 있지 않고 우리 모두에게 있다는 문화를 만드는 데에 있다고 할 수 있다.
코드리뷰의 중요성 및 장점#
코드리뷰로 얻을 수 있는 가장 대표적인 장점으로는 ‘버그의 조기 발견’, ‘개발 표준(convention) 준수’, ‘중복 코드를 방지하고 모듈의 재사용성 증대’와 같은 것들 외에도 많은것들이 있다.
본인은 쉽게 발견하지 못하는 실수를 다른 사람은 금방 발견하여 코드의 부작용(side effect)과 오류를 좀 더 일찍 조치할 수 있으며, 정해진 표준 준수를 통해서 많은 사람들의 개발 결과물이 일관된 스타일을 유지할 수 있도록 도와준다. 또한, 동일한 역할을 수행하는 중복 코드를 빨리 발견하고 이미 만들어진 코드를 재사용할 수 있도록 수정할 수 있다.
“코드 컴플릿(Code Complete)”의 저자 스티브 맥코넬(Steve McConnell)은 책에 서 다음과 같은 실험결과를 통해 코드리뷰의 중요성을 강조합니다.
“소프트웨어를 유지보수하는 조직에서 코드 한 줄을 변경한다고 했을 때, 코드리뷰가 도입되기 전에는 그러한 변경의 55% 정도가 문제를 일으켰다. 그러나 리뷰 과정이 도입된 이후에는 그러한 변경의 2% 정도에서만 문제가 발생했다.”
코드 리뷰의 또 다른 장점으로는 다른 사람의 잘 만들어진 코드를 보면서 배울 기회를 얻을 수 있다. 같은 환경에서 개발을 진행하더라도 개인별로 해당 언어나 프레임워크에 대한 이해도와 경험은 크게 차이가 날 수 있다.
예를들어 코드를 작성하는 사람마다 여러 성향이 있을 수 있다.
- 프로그래밍 언어와 프레임워크가 추구하고자 하는 기본 철학을 이해하고 그에 맞는 방식을 유지하려고 노력하는 사람
- 기존에 다른 환경에서 개발하던 방식을 벗어나지 못하고 현재 환경의 장점을 활용하지 못하는 사람
- 언어나 프레임워크가 기본적으로 제공하는 손쉬운 기능들을 잘 숙지하고 적절히 활용하는 사람
- 이미 만들어져 있는 기능을 사용하지 못하고 직접 불필요한 기능을 추가하는 사람
- etc..
이러한 여러 성향 및 개인 간의 격차를 해소하는 가장 좋은 방법이 바로 코드리뷰이며 이를 통해 조금 더 좋은 방법을 제시해주고 이해 수준을 상향 평준화하는 것이 될 수 있다.
즉, 코드리뷰는 단순히 버그를 사전에 발견하거나 문제점을 찾는 목적을 넘어서 전체적인 조직의 역량을 강화하는 중요한 역할을 한다.
그럼에도 코드리뷰의 가장 중요한 점 한 가지를 뽑는다면 ‘책임자를 추궁하지 않는 문화’의 정착이라고 말하고 싶습니다.
Logi-Spot 코드리뷰
코드리뷰시 확인해야할 것#
기능의정상동작여부#
기본적으로 모든 코드는 존재하는 목적을 가지고 있습니다. 다른 조건을 모두 만족하더라도 원하는 대로 동작하지 않는 코드는 잘못된 코드라고 할 수 있습니다. 코드리뷰의 시작과 끝은 언제나 기능이 원하는 대로 정상 동작하는지 확인하는 작업이 필수
버그의 조기 발견#
코드 리뷰로 얻을 수 있는 장점 중 하나는 버그를 조기에 발견하여 불필요한 비용을 절감할 수 있다.
같은 버그라고 해도 해당 버그를 코드리뷰 단계에서 발견하는 것과 테스트 단계에서 발견하는 것, 그리고 배포 이후에 발견하는 것은 순서대로 더 비싼 비용을 지불해야 하며, 코드리뷰를 할 때는 버그가 발생할 소지가 없는지 점검해야 한다.
가독성과 유지보수 편의성#
가독성과 유지보수 편의성은 자칫 잘못하면 주관적인 견해로 옳고 그름을 따지는 비생산적 논쟁으로 변질될 수 있으므로 가급적 기준을 정하고 해당 기준을 기반으로 검토하는 것이 좋다.
예를 들어, 들여쓰기(indent)의 크기나, 코드 한 줄의 최대 길이, 메소드 호출의 깊이(depth)등의 표준을 정해두면 좀 더 객관적인 기준으로 코드리뷰를 수행할 수 있습니다.
아이랩 팀은 한라인 80줄, 들여쓰기 2칸규칙이 적용중이다. (메소드 호출 길이는..음)
개발 표준(CONVENTION)의 준수 여부#
개발 표준을 잘 정리하고 지키려는 활동이 계속되면 많은 사람이 함께 개발하더라도 어느정도 일관된 개발 스타일을 유지할 수 있다.
테스트 코드의 작성 여부#
모든 개발자가 테스트 코드 작성을 당연시하고 습관적으로 수행하면 더 바랄 것이 없지만, 만약 그렇지 않다면 어느 정도 강제성을 통해 습관을 만들어나가는 노력이 필요하다.
이런 상황에 적합한 것이 바로 코드 리뷰시 테스트 코드의 작성 여부를 확인하는 것.
실제로 수많은 개발자가 동시에 개발을 진행하는 오픈소스 프로젝트들 대부분은 Pull Request 의 기본 조건으로 테스트 코드의 제출을 요구합니다.
테스트 코드를 작성하는 문화는 수많은 개발 조직에서 시도하지만 쉽게 정착하기 힘든 개발 문화 중 하나입니다.
재사용 가능한 모듈의 중복 개발#
개발을 진행하다 보면, 자주 사용할 것 같은 기능들을 모듈화하여 재사용할 수 있도록 만드 는 경우가 많다. 하지만 모듈을 공유하고 모두가 기억하도록 하는 것은 생각처럼 쉽지 않은 일이다.
코드리뷰는 같은 기능을 하는 중복된 모듈의 개발을 막고, 코드의 재사용을 높이는 아주 좋은 방법이다.
만약, 누군가가 재활용할 수 있는 기존 코드를 인지하지 못하고 스스로 중복된 코드를 만들었다면, 코드리뷰 과정에서 같은 기능을 하는 코드가 존재한다는 피드백을 받아 수정할 수 있다.
배울만한 점은 없는지#
코드리뷰에 많은 사람이 오해하는 부분 중 하나는, 경력이 많거나 실력이 뛰어난 개발자가 후배 개발자의 코드를 검사한다고 생각하는 것이다.
코드리뷰의 목적은 코드 작성자에 게 피드백을 주는 것도 있지만, 해당 코드를 보면서 ‘아, 이런 식으로 코드를 작성하는 것도 가능하구나?’, ‘아, 이렇게 쉬운 방법이 있었구나?’와 같은 학습효과도 함께 가지고 있다.
그렇기 때문에 코드를 리뷰할 때는 피드백을 주기 위한 시각과 좋은 점을 배우려는 시각, 이 두 가지 시각의 균형을 맞추며 진행하는 것이 좋다.
글로벌 기업의 코드리뷰#
구글 코드리뷰 연습
구글은 100% 코드 리뷰, 모든 코드를 리뷰한다고 한다.
물론 Tricorder라는 정적 분석(잠재결함 분석) 도구와 Rosie라는 코드 정리 시스템(Large-Scale Cleanups and Code Changes)을 활용해 사용하지 않는 코드는 없애고 리팩토링이 필요한 경우에 효율적으로 리뷰를 한다고 알려져있다.
Microsoft#
개발자 업무는 개발 50%, 리뷰 50%인 Microsoft
Microsoft의 개발자라면 매일 코드 리뷰를 해야 합니다. Microsoft의 전체 직원 수는 14만 명이고, 이중 44%인 6만 명에 이르는 개발자의 75%가 매일 코드 리뷰를 하고 있다고 알려져 있다.
“리뷰는 당연하다”, 네카라쿠배*와 스타트업#
국내 스타트업을 중심으로 자동화된 배포와 테스트는 이제 기본기 중의 기본기가 되었다.
테스트 기반의 코딩인 TDD(Test Driven Development)를 필수로 적용하고, 코드 Merge 전에 코드 리뷰는 필수적인 프로세스가 되었다.
국내 IT 선도기업들은 회사에서 표준을 제공하기보다는 팀 상황에 맞추어 자율적으로 코드 리뷰 방법을 결정해서 자율적으로 적용하고 있지만, 대부분의 회사는 GitHub에서 제공하는 PR(Pull Request)을 활용해서 리뷰 요청과 검토를 완료(Approve)하는 방식으로 코드 리뷰를 진행한다고 한다.
우리팀은..?#
현재 아이랩팀은 현재 GitHub에서 Master Branch만 사용중이다.
그 후 로컬환경에서 코드를 작성 Merge후 바로 커밋후 저장소에 Push를 진행하고있다.
앞으로 Pull Request 템플릿을 활용해 필요한 작업은 반드시 코드리뷰 후 Master 브랜치에 Merge를 진행할 예정이다.
- develop 브랜치 생성(Develop에 푸쉬 시, 반드시 Reviewer 한명이상 지정)
- 각자 브랜치를 생성하여 작업
- develop 브랜치에 머지 진행전 PR(Pull Request)를 통한 코드리뷰
- develop에 모두 merge된 소스를 배포시 master에 병합하여 어플리케이션 버전업