2021년 7월
2021-07-06#
합병 정렬(merge sort)#
합병 정렬(merge sort) 알고리즘 개념 요약#
- '존 폰 노이만(John von Neumann)'이라는 사람이 제안한 방법.
- 일반적인 방법으로 구현했을 때 이 정렬은 안정 정렬 에 속하며, 분할 정복 알고리즘의 하나 이다.
- 분할 정복(divide and conquer) 방법
- 문제를 작은 2개의 문제로 분리하고 각각을 해결한 다음, 결과를 모아서 원래의 문제를 해결하는 전략이다.
- 분할 정복 방법은 대개 순환 호출을 이용하여 구현한다.
- 분할 정복(divide and conquer) 방법
- 과정 설명
- 리스트의 길이가 0 또는 1이면 이미 정렬된 것으로 본다. 그렇지 않은 경우에는
- 정렬되지 않은 리스트를 절반으로 잘라 비슷한 크기의 두 부분 리스트로 나눈다.
- 각 부분 리스트를 재귀적으로 합병 정렬을 이용해 정렬한다.
- 두 부분 리스트를 다시 하나의 정렬된 리스트로 합병한다.
합병 정렬(merge sort) 알고리즘의 구체적인 개념#
- 하나의 리스트를 두 개의 균등한 크기로 분할하고 분할된 부분 리스트를 정렬한 다음, 두 개의 정렬된 부분 리스트를 합하여 전체가 정렬된 리스트가 되게 하는 방법이다.
- 합병 정렬은 다음 단계들로 이루어진다.
- 분할(Divide): 입력 배열을 같은 크기의 2개의 부분 배열로 분할한다.
- 정복(Conquer): 부분 배열을 정렬한다. 부분 배열의 크기가 충분히 작지 않으면 순환 호출을 이용하여 다시 분할 정복 방법을 적용한다.
- 결합(Combine): 정렬된 부분 배열들을 하나의 배열에 합병한다.
- 합병 정렬의 과정
- 추가적인 리스트가 필요하다.
- 각 부분 배열을 정렬할 때도 합병 정렬을 순환적으로 호출하여 적용한다.
- 합병 정렬에서 실제로 정렬이 이루어지는 시점은 2개의 리스트를 합병(merge)하는 단계이다.
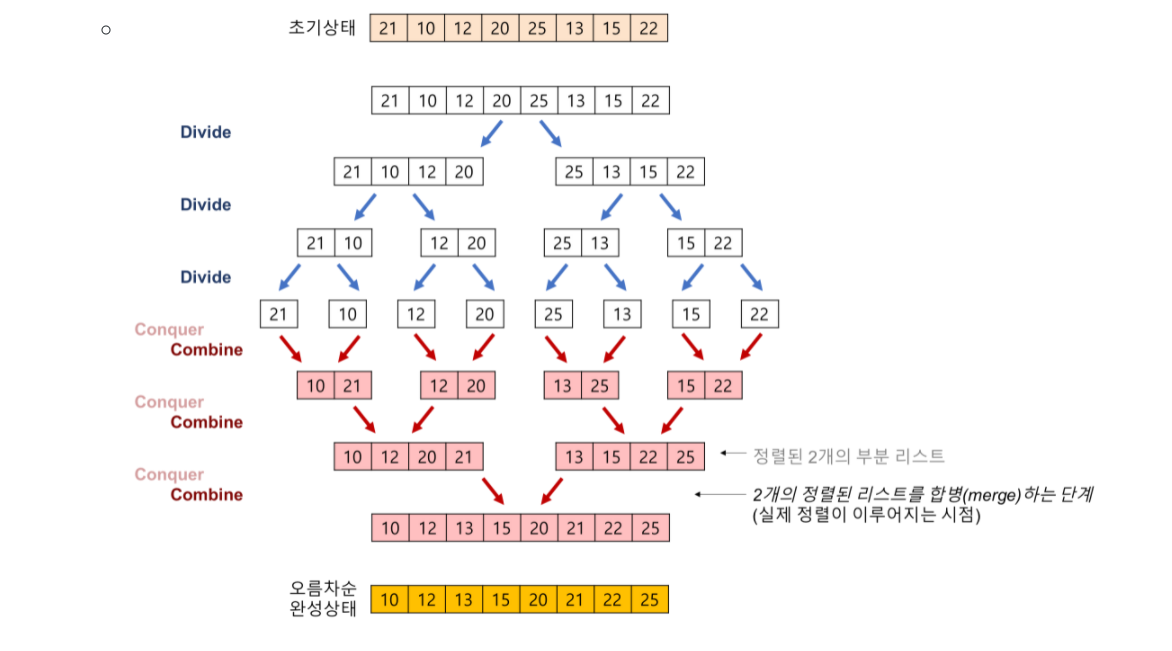
합병 정렬(merge sort) 알고리즘의 예제#
- 배열에 27, 10, 12, 20, 25, 13, 15, 22이 저장되어 있다고 가정하고 자료를 오름차순으로 정렬해 보자.
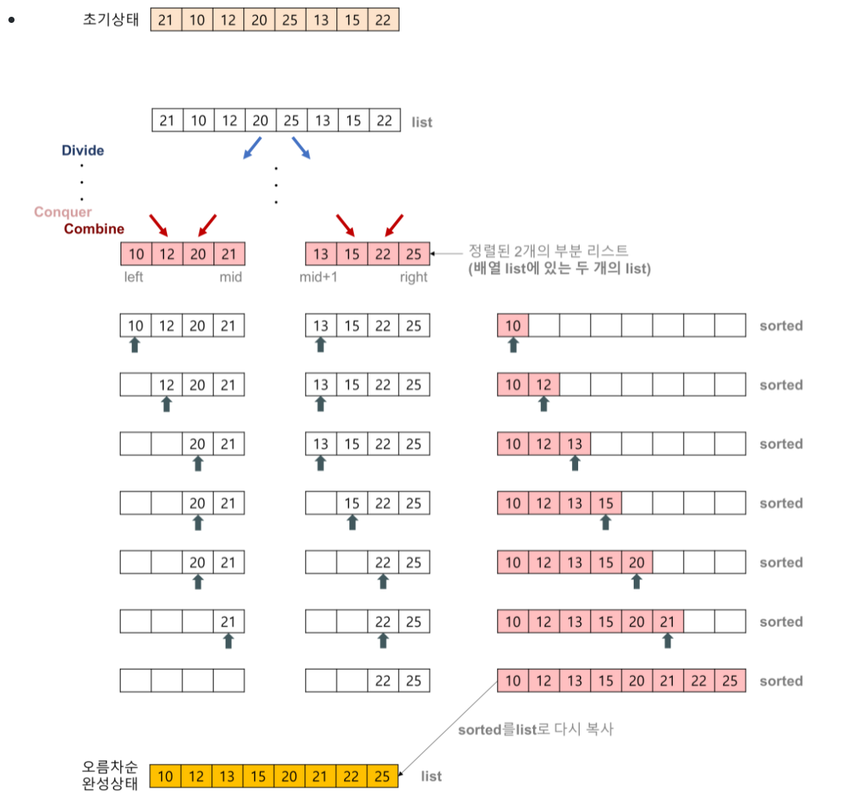
- 2개의 정렬된 리스트를 합병(merge)하는 과정
- 2개의 리스트의 값들을 처음부터 하나씩 비교하여 두 개의 리스트의 값 중에서 더 작은 값을 새로운 리스트(sorted)로 옮긴다.
- 둘 중에서 하나가 끝날 때까지 이 과정을 되풀이한다.
- 만약 둘 중에서 하나의 리스트가 먼저 끝나게 되면 나머지 리스트의 값들을 전부 새로운 리스트(sorted)로 복사한다.
- 새로운 리스트(sorted)를 원래의 리스트(list)로 옮긴다.
구현 코드#
합병 정렬(merge sort) 알고리즘의 특징#
- 장점
- 안정적인 정렬 알고리즘
- 자료구조를 리스트로 구성하면 링크 인덱스만 변경되므로 데이터 이동은 현저히 감소
- 데이터의 분포에 영향을 덜 받으므로 입력된 자료들에 영향을 받지 않고 정렬되는 시간이 동일
- 단점
- 병합하는 과정에서 입력 자료들의 크기(n)만큼의 메모리가 추가적으로 필요
- 만약, 자료구조를 배열로 구성할 경우 입력 자료의 크기가 크게 되면 이동횟수가 많아 낭비
합병 정렬(merge sort)의 시간복잡도#
시간 복잡도를 계산한다면
- 분할 단계
- 비교 연선과 이동 연산이 수행되지 않는다.
- 합병 단계
- 비교 횟수
- 순환 호출의 깊이(합병 단계의 수)
- 레코드의 개수 n이 2의 거듭제곱이라고 가정(n=2^k)했을 때, n=2^3의 경우, 2^3 -> 2^2 -> 2^1 -> 2^0 순으로 줄어들어 순환 호출의 깊이가 3임을 알 수 있다. 이것을 일반화하면 n=2^k의 경우, k(k=log₂n)임을 알 수 있다.
- k=log2n
- 각 합병 단계의 비교 연산
- 크기 1인 부분 배열 2개를 합병하는 데는 최대 2번의 비교 연산이 필요하고, 부분 배열의 쌍이 4개이므로 24=8번의 비교 연산이 필요하다. 다음 단계에서는 크기 2인 부분 배열 2개를 합병하는 데 최대 4번의 비교 연산이 필요하고, 부분 배열의 쌍이 2개이므로 42=8번의 비교 연산이 필요하다. 마지막 단계에서는 크기 4인 부분 배열 2개를 합병하는 데는 최대 8번의 비교 연산이 필요하고, 부분 배열의 쌍이 1개이므로 8*1=8번의 비교 연산이 필요하다. 이것을 일반화하면 하나의 합병 단계에서는 최대 n번의 비교 연산을 수행함을 알 수 있다.
- 최대 n번
- 순환 호출의 싶이 만큼의 합병 단계 * 각 합병 단계의 비교 연산 = nlog2n
- 이동 횟수
- 순환 호출의 깊이(합병 단계의 수)
- k=log2n
- 각 합병 단계의 이동 연산
- 임시 배열에 복사했다가 다시 가져와야 되므로 이동 연산은 총 부분 배열에 들어 있는 요소의 개수가 n인 경우, 레코드의 이동이 2n번 발생한다.
- 순환 호출의 싶이 만큼의 합병 단계 * 각 합병 단계의 이동연산 = 2nlog2n
- 순환 호출의 깊이(합병 단계의 수)
- T(n) = nlog₂n(비교) + 2nlog₂n(이동) = 3nlog₂n = O(nlog₂n)
정렬 알고리즘 시간 복잡도 비교#
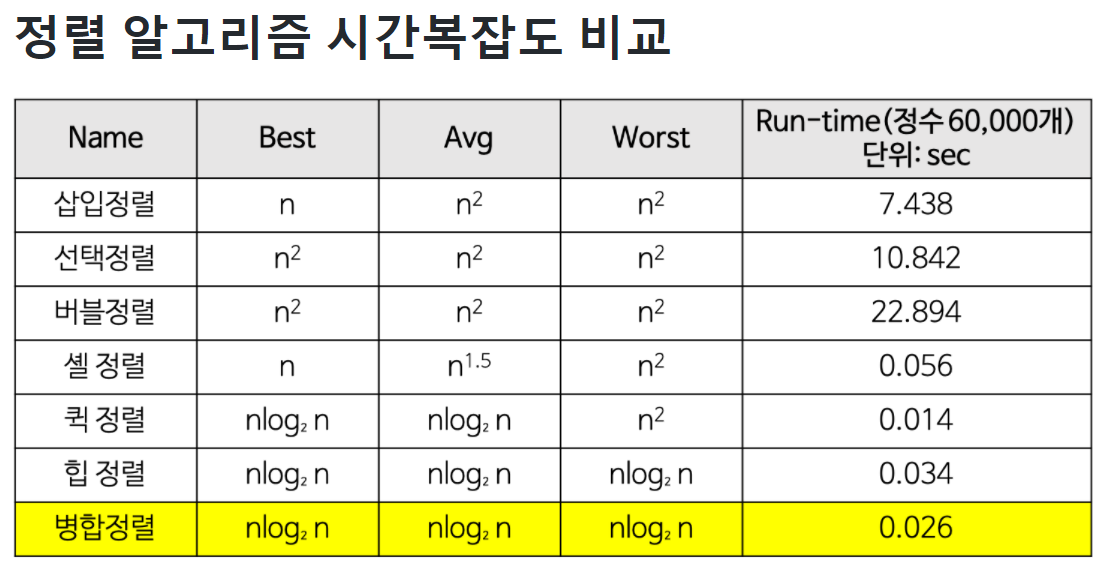
출처:https://gmlwjd9405.github.io/2018/05/08/algorithm-merge-sort.html
2021-07-13#
퀵 정렬(quick sort)#
퀵 정렬(quick sort) 알고리즘의 개념 요약#
- ‘찰스 앤터니 리처드 호어(Charles Antony Richard Hoare)’가 개발한 정렬 알고리즘
- 퀵 정렬은 불안정 정렬에 속하며, 다른 원소와의 비교만으로 정렬을 수행하는 비교 정렬에 속한다.
- 분할 정복 알고리즘의 하나로, 평균적으로 매우 빠른 수행 속도를 자랑하는 정렬 방법
- 합병 정렬(merge sort)과 달리 퀵 정렬은 리스트를 비균등하게 분할한다.
- 분할 정복(divide and conquer) 방법
- 문제를 작은 2개의 문제로 분리하고 각각을 해결한 다음, 결과를 모아서 원래의 문제를 해결하는 전략이다.
- 분할 정복 방법은 대개 순환 호출을 이용하여 구현한다.
- 과정 설명
- 리스트 안에 있는 한 요소를 선택한다. 이렇게 고른 원소를 피벗(pivot)이라고 한다.
- 피벗을 기준으로 피벗보다 작은 요소들은 모두 피벗의 왼쪽으로 옮겨지고 피벗보다 큰 요소들은 모두 피벗의 오른쪽으로 옮겨진다. (피벗을 중심으로 왼쪽: 피벗보다 작은 요소들, 오른쪽: 피벗보다 큰 요소들)
- 피벗을 제외한 왼쪽 리스트와 오른쪽 리스트를 다시 정렬한다.
- 분할된 부분 리스트에 대하여 순환 호출 을 이용하여 정렬을 반복한다.
- 부분 리스트에서도 다시 피벗을 정하고 피벗을 기준으로 2개의 부분 리스트로 나누는 과정을 반복한다.
- 부분 리스트들이 더 이상 분할이 불가능할 때까지 반복한다. - 리스트의 크기가 0이나 1이 될 때까지 반복한다.
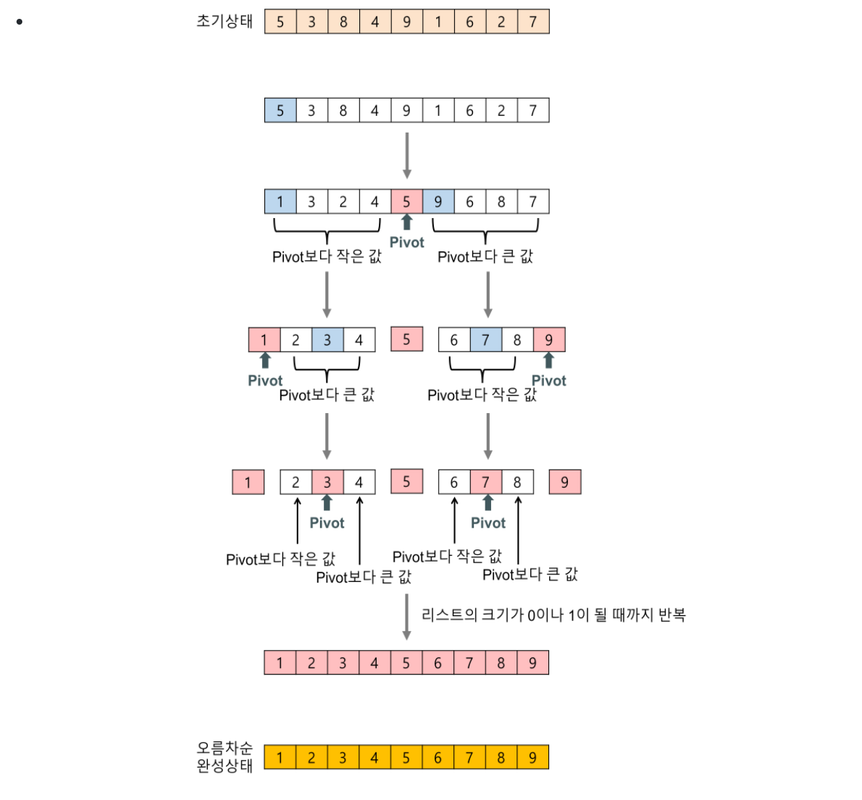
퀵 정렬(quick sort) 알고리즘의 예제#
- 배열에 5,3,8,4,9,1,6,2,7 이 저장되어 있다고 가정하고 자료를 오름차순으로 정렬해 보자.
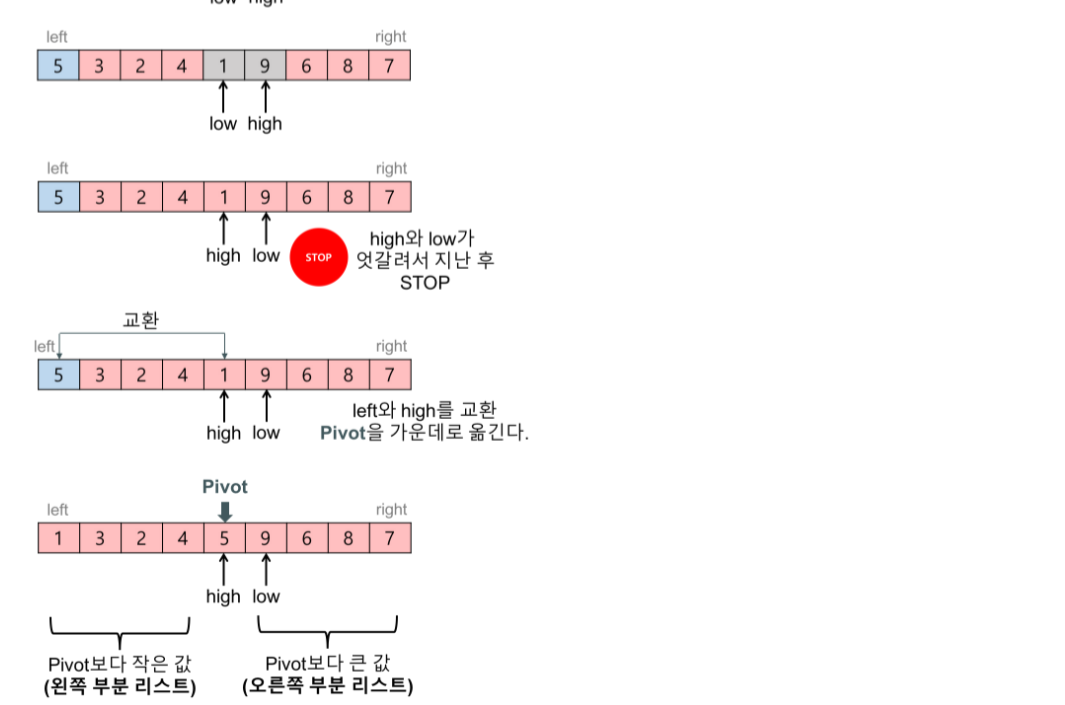
- 퀵 정렬에서 피벗을 기준으로 두개의 리스트로 나누는 과정(partition 함수의 내용)

- 피벗 값을 입력 리스트의 첫 번째 데이터로 하자. (다른 임의의 값이어도 상관없다.)
- 2개의 인덱스 변수(low, high)를 이용해서 리스트를 두개의 부분 리스트로 나눈다.
- 1회전: 피벗이 5인 경우,
- low는 왼쪽에서 오른쪽으로 탐색해가다가 피벗보다 큰 데이터(8)을 찾으면 멈춘다.
- high는 오른쪽에서 왼쪽으로 탐색해가다가 피벗보다 작은 데이터(2)를 찾으면 멈춘다.
- low와 high가 가리키는 두 데이터를 서로 교환한다.
- 이 탐색-교환 과정은 low와 high가 엇갈릴 때까지 반복한다.
- 2회전: 피벗(1회전의 왼쪽 부분리스트의 첫 번째 데이터)이 1인 경우,
- 위와 동일한 방법으로 반복한다.
- 3회전: 피벗(1회전의 오른쪽 부분리스트의 첫 번째 데이터)이 9인 경우,
- 위와 동일한 방법으로 반복한다.
퀵 정렬(quick sort) JavaScript 코드#
퀵 정렬(quick sort) 알고리즘의 특징#
장점
속도가 빠르다.
- 시간 복잡도가 O(nlog2n)를 가지는 다른 정렬 알고리즘과 비교했을 때도 가장 빠르다.
추가 메모리 공간을 필요로 하지 않는다.
- 퀵 정렬은O(log n)만큼의 메모리를 필요로 한다.
단점
- 정렬된 리스트에 대해서는 퀵 정렬의 불균형 분할에 의해 오히려 수행시간이 더 많이 걸린다.
퀵 정렬의 불균형 분할을 방지하기 위하여 피벗을 선택할 때 더욱 리스트를 균등하게 분할할 수 있는 데이터를 선택한다.
- ex) 리스트 내의 몇 개의 데이터 중에서 크기순으로 중간 값(medium)을 피벗으로 선택한다.
퀵 정렬(quick sort)의 시간복잡도#
- 평균T(n) = O(nlog2n)
- 시간 복잡도가 O(nlog2n)를 가지는 다른 정렬 알고리즘과 비교했을 때도 가장 빠르다.
- 퀵 정렬이 불필요한 데이터의 이동을 줄이고 먼거리의 데이터를 교환할 뿐만 아니라, 한 번 결정된 피벗들이 추후 연산에서 제외되는 특성때문이다.
정렬 알고리즘 시간복잡도 비교#
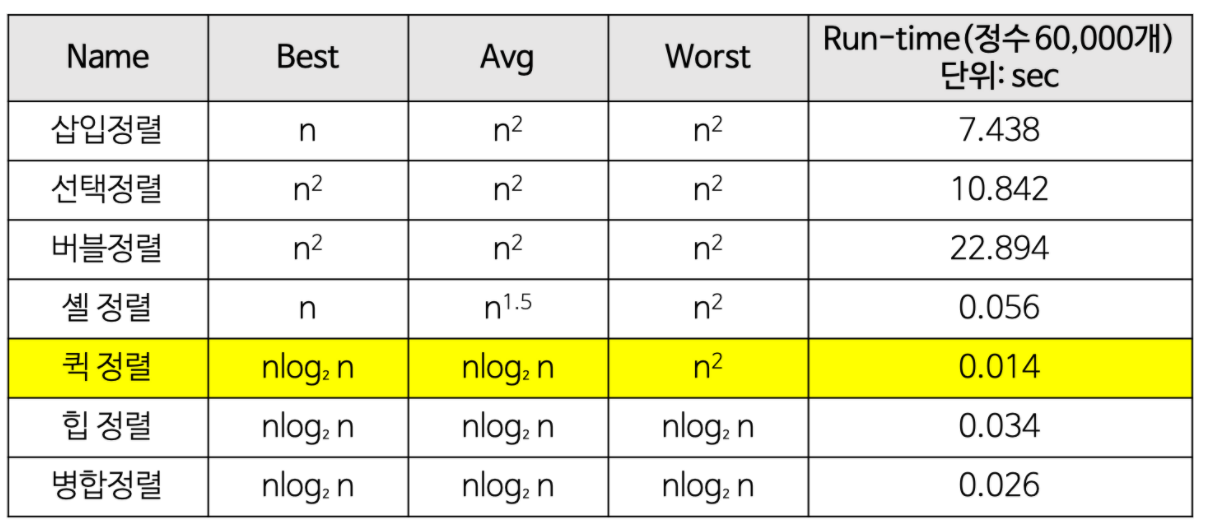
출처:https://gmlwjd9405.github.io/2018/05/10/algorithm-quick-sort.html
2021-07-20#
힙 정렬(heap sort)#
힙 정렬(heap sort) 알고리즘의 개념 요약#
- 최대 힙(max heap) 트리나 최소 힙(min heap) 트리를 구성해 정렬을 하는 방법
- 내림차순 정렬을 위해서는 최대 힙을 구성하고 오름차순 정렬을 위해서는 최소 힙을 구성하면 된다.
- 과정 설명
- 정렬해야 할 n개의 요소들로 최대 힙(완전 이진 트리 형태)을 만든다.
- 그 다음으로 한 번에 하나씩 요소(루트 노드의 값)를 힙에서 꺼내서 배열의 뒤부터 저장하면 된다.
- 삭제되는 요소들(최대값부터 삭제)은 값이 감소되는 순서로 정렬되게 된다.
자료구조 힙(heap)#
- 완전 이진 트리의 일종으로 우선순위 큐를 위하여 만들어진 자료구조이다.
- 여러 개의 값들 중에서 최대값이나 최솟값을 빠르게 찾아내도록 만들어진 자료구조이다.
- 힙은 일종의 반정렬 상태(느슨한 정렬 상태) 를 유지한다.
- 큰 값이 상위 레벨에 있고 작은 값이 하위 레벨에 있다는 정도
- 간단히 말하면 부모 노드의 키 값이 작식 노드의 키 값보다 항상 큰(작은) 이진 트리를 말한다.
- 힙 트리에서는 중복된 값을 허용한다. (이진 탐색트리에서는 중복된 값을 허용하지 않는다.)
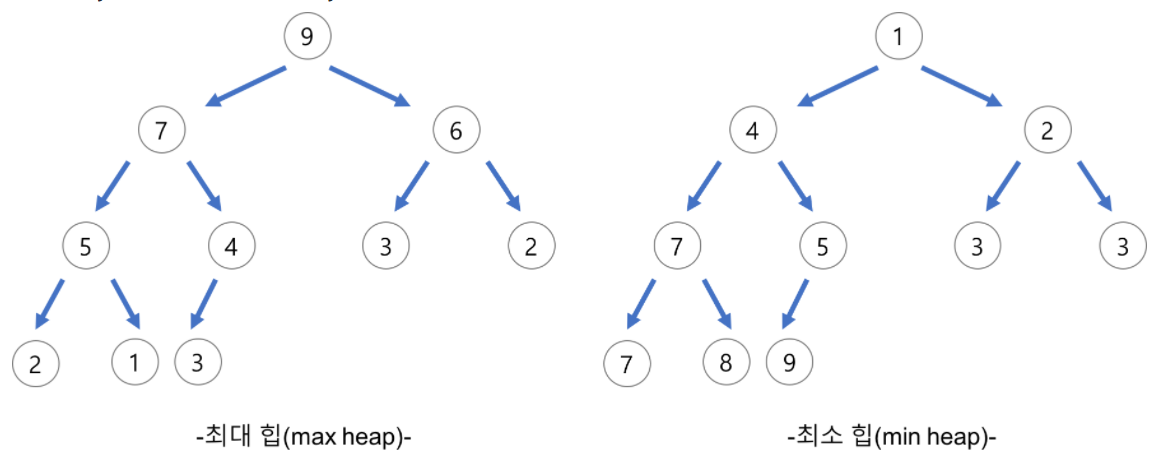
힙(heap)의 종류#
- 최대 힙(max heap)
- 부모 노드의 키 값이 자식 노드의 키 값보다 크거나 같은 완전 이진 트리
- key(부모 노드) >= key(자식 노드)
- 최소 힙(min heap)
- 부모 노드의 키 값이 자식 노드의 키 값보다 작거나 같은 완전 이진 트리
- key(부모 노드) <= key(자식 노드)
힙(heap)의 구현#
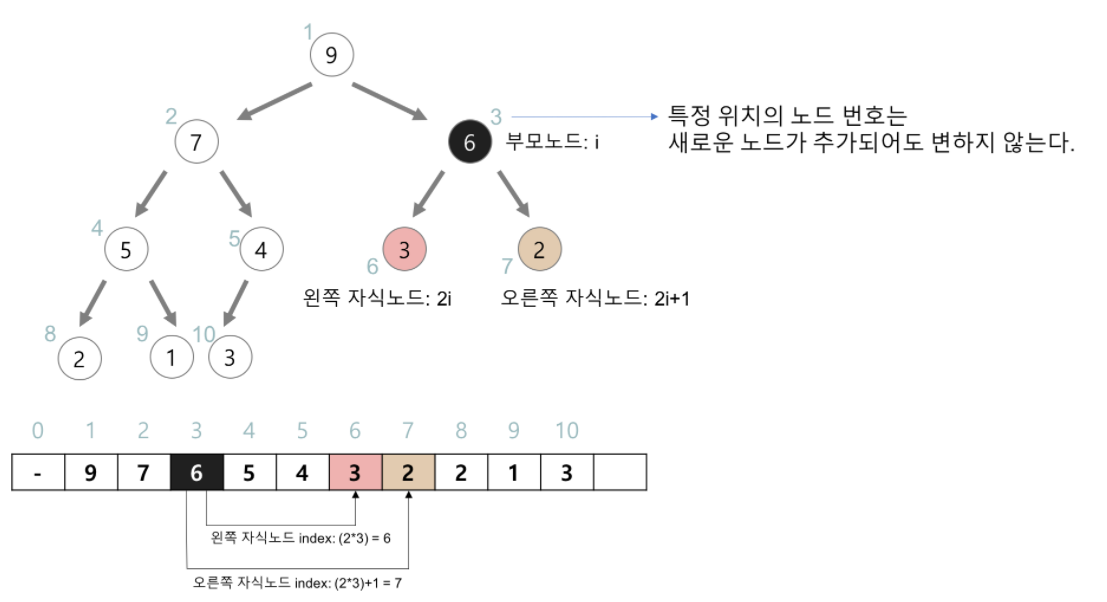
- 힙을 저장하는 표준적인 자료구조는 배열 이다.
- 특정 위치의 노드 번호는 새로운 노드가 추가되어도 변하지 않는다.
- 예를 들어 루트 노드의 오른쪽 노드의 번호는 항상 3이다.
- 힙에서의 부모 노드와 자식 노드의 관계
- 왼쪽 자식의 인덱스 = (부모의 인덱스)*2
- 오른쪽 자식의 인덱스 = (부모의 인덱스)*2 + 1
- 부모의 인덱스 = (자식의 인덱스) / 2
힙(heap)의 삽입#
- 힙에 새로운 요소가 들어오면, 일단 새로운 노드를 힙의 마지막 노드에 이어서 삽입한다.
- 새로운 노드를 부모 노드들과 교환해서 힙의 성질을 만족시킨다.
- 아래의 최대 힙(max heap)에 새로운 요소 8를 삽입해보자.
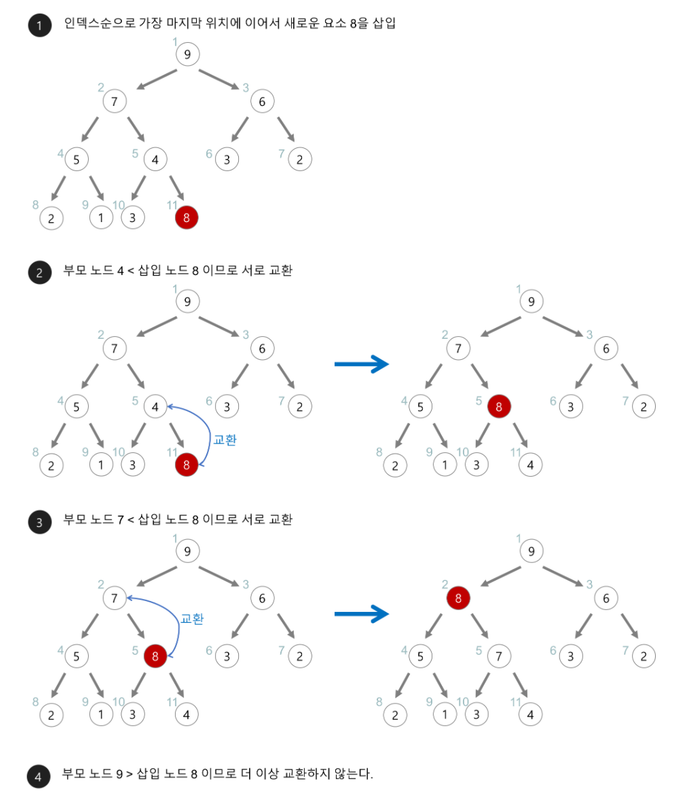
출처: https://gmlwjd9405.github.io/2018/05/10/algorithm-heap-sort.html
힙(heap)의 삭제#
- 최대 힙에서 최대값은 루트 노드이므로 루트 노드가 삭제된다.
- 최대 힙(max heap)에서 삭제 연산은 최대값을 가진 요소를 삭제하는 것이다.
- 삭제된 루트 노드에는 힙의 마지막 노드를 가져온다.
- 힙을 재구성한다.
- 아래의 최대 힙(max heap)에서 최대값을 삭제해보자.
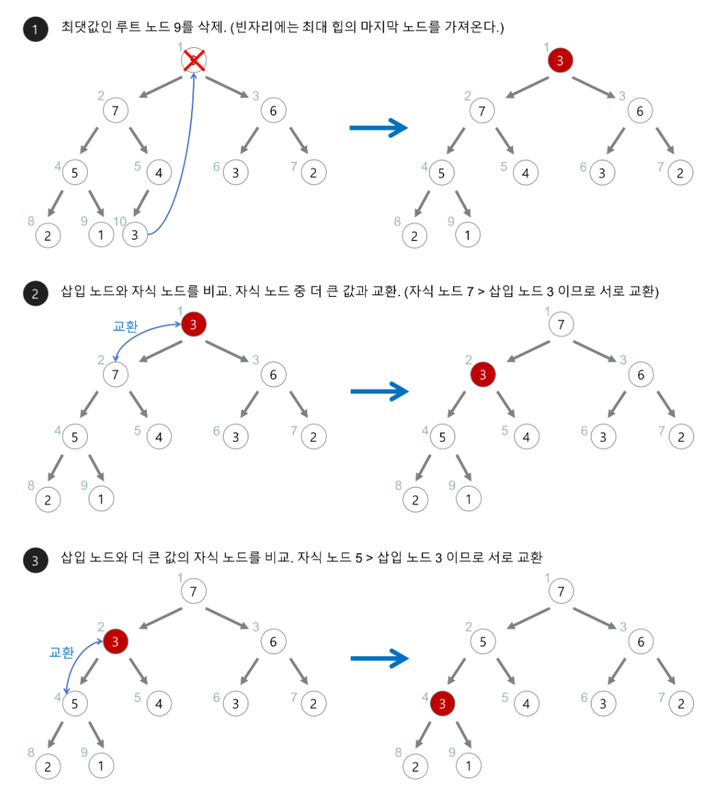
출처: https://gmlwjd9405.github.io/2018/05/10/algorithm-heap-sort.html
힙 정렬(heap sort) 알고리즘의 c언어 코드#
출처: https://gmlwjd9405.github.io/2018/05/10/algorithm-heap-sort.html
힙 정렬(heap sort) 알고리즘의 특징#
- 장점
- 시간 복잡도가 좋은편
- 힙 정렬이 가장 유용한 경우는 전체 자료를 정렬하는 것이 아니라 가장 큰 값 몇개만 필요할 때 이다.
힙 정렬(heap sort)의 시간복잡도#
- 힙 트리의 전체 높이가 거의 log2n(완전 이진 트리이므로)이므로 하나의 요소를 힙에 삽입하거나 삭제할 때 힙을 재정비하는 시간이 log2n만큼 소요된다.
- 요소의 개수가n개 이므로 전체적으로 O(nlog2n)의 시간이 걸린다.
- T(n) = O(nlog2n)
정렬 알고리즘 시간복잡도 비교#
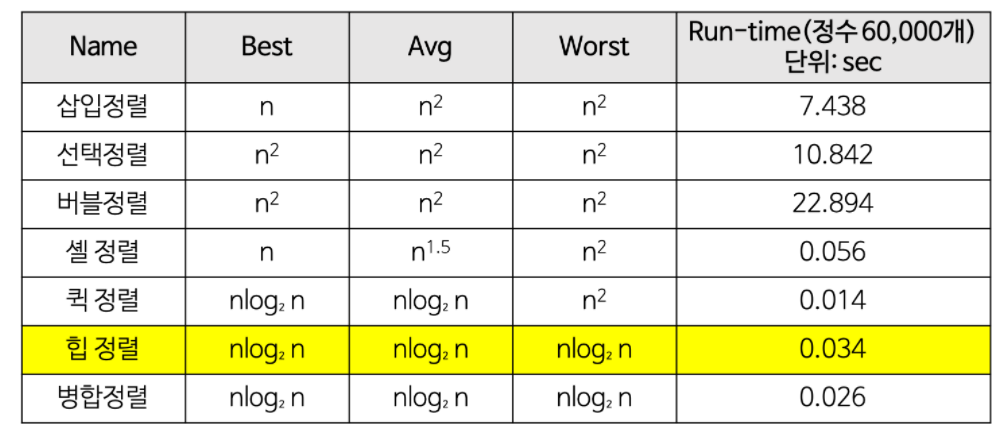
출처:https://gmlwjd9405.github.io/2018/05/10/algorithm-heap-sort.html
2021-07-27#
함수 생성 방식#
함수 선언(function declaration)#
- function 키워드, 함수 이름, 괄호로 둘러싼 매개변수를 차례로 써주면 함수를 선언할 수 있습니다. 위 함수에는 매개변수가 없는데, 만약 매개변수가 여러 개 있다면 각 매개변수를 콤마로 구분해 줍니다. 이어서 함수를 구성하는 코드의 모임인 '함수 본문(body)'을 중괄호로 감싸 붙여줍시다.
- 함수 선언문이라고 부르기도 한다.
함수 표현식(Function Expression)#
- 함수를 생성하고 변수에 값을 할당하는 것처럼 하는 방식
함수 표현식 vs 함수 선언문#
- 문법
- 함수 선언문: 함수는 주요 코드 흐름 중간에 독자적인 구문 형태로 존재합니다.
- 함수 표현식: 함수는 표현식이나 구문 구성(syntax construct) 내부에 생성된다.
- 함수 생성 시점
- 함수 표현식: 실제 실행 흐름이 해당 함수에 도달했을 때 함수를 생성합니다. 따라서 실행 흐름이 함수에 도달했을 때부터 함수를 사용할 수 있습니다.
- 함수 선언문: 함수 선언문이 정의되기 전에도 호출할 수 있습니다.
- 스코프
- 함수 선언문: 엄격 모드에서 함수 선언문이 코드 블록 내에 위치하면 해당 함수는 블록 내 어디서든 접근할 수 있지만 블록 밖에서는 함수에 접근하지 못한다.
- 함수 표현식: 코드 블록 밖에서도 함수에 접근할 수 있다.
화살표 함수(arrow function)#
- 함수 표현식을 보다 단순하고 간결하게 만드는 문법
이렇게 코드를 작성하면 인자 arg1..argN를 받는 함수 func이 만들어집니다. 함수 func는 화살표(=>) 우측의 표현식(expression)을 평가하고, 평가 결과를 반환합니다.
아래 함수의 축약 버전이라고 할 수 있죠.
- 구체적인 예시
- 인수가 하나밖에 없다면 인수를 감싸는 괄호를 생략할 수 있다.
- 인수가 하나도 없을 경우
- 본문이 여러 줄인 화살표 함수
기명 함수 표현식(Named Function Expression, NFE)#
- 이름이 있는 함수 표현식을 나타내는 용어
- 이름을 사용해서 함수 표현식 내부에서 자기 자신을 참조할 수 있다.
- 기명 함수 표현식 외부에선 그 이름을 사용할 수 없다.
- 기명 함수를 사용하지 않고 내부에서 호출할 경우 외부 코드에 의해 변경될 수 있다는 문제가 생긴다.
new Function 문법#
- new Function 문법을 사용하면 함수를 만들 수 있다.
새로 만들어지는 함수는 인수 arg1...argN과 함수 본문 functionBody로 구성된다.
- 인수가 없고 본문만 있는 함수