GraphQL Architecture & Use Case
2021-03-09#
List#
- GraphQL
- REST vs GraphQL
- Schema
- Query
REST vs GraphQL#
GraphQL은 원하는 데이터를 선언하여 data fetching이 가능하다.
- 만약 블로그 어플리케이션을 시작한다면
- 사용자의 정보
- 마지막에 생성한 게시물
- 팔로워
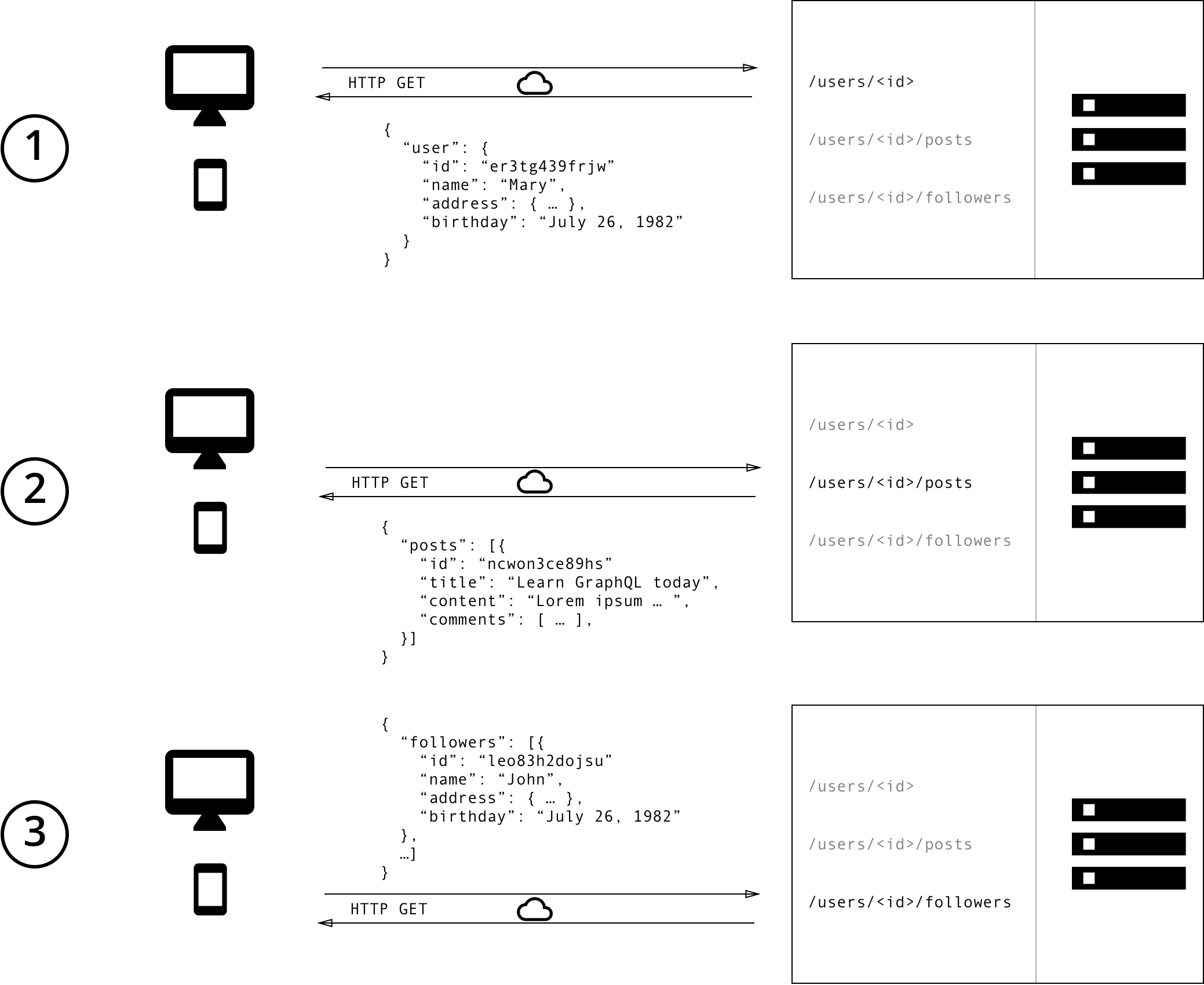
REST로 데이터 패칭#
GraphQL로 데이터 패칭#
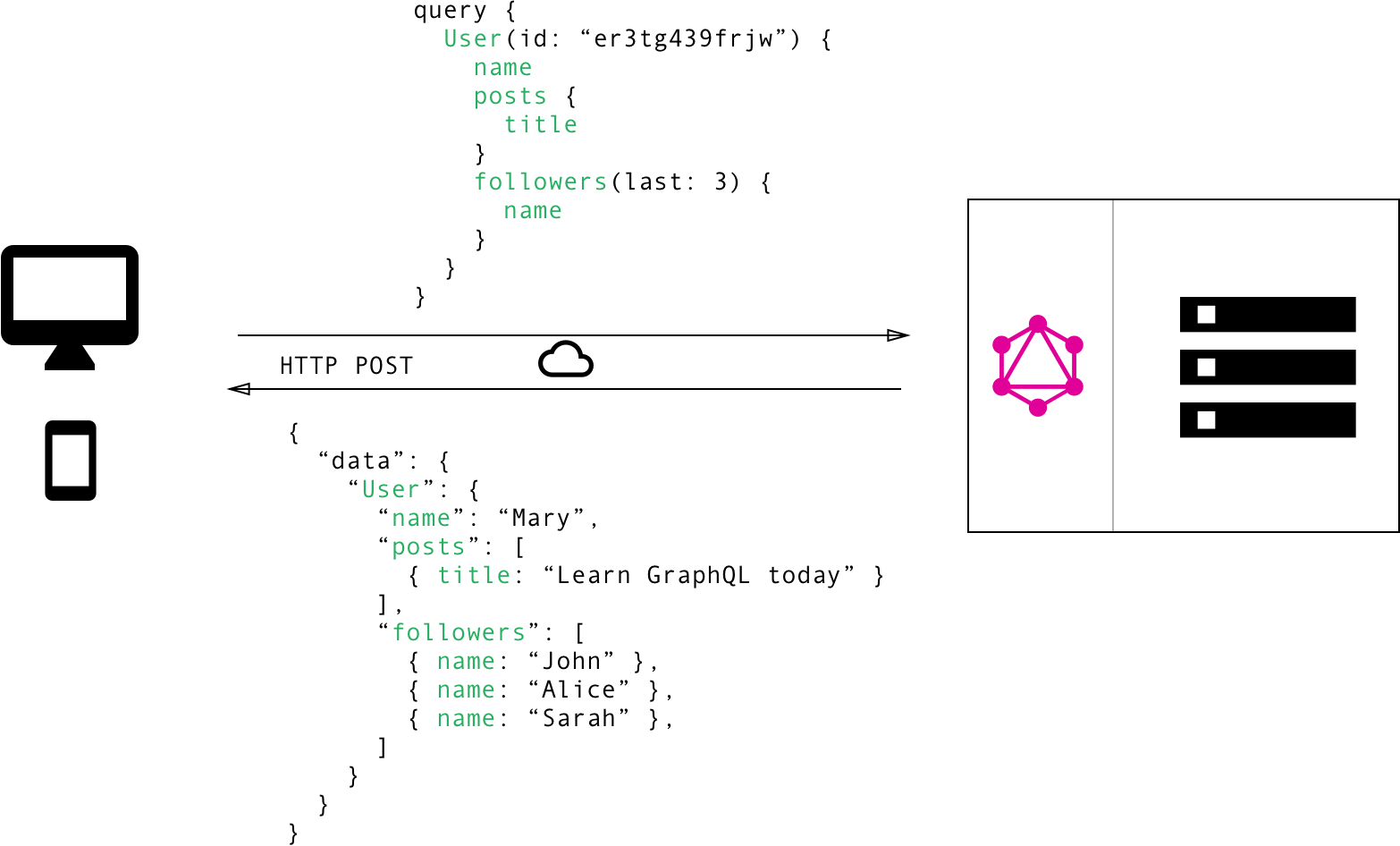
- 오버페치, 언더페치 방지
- API를 호출 후 여러번 가져와야되는 n+1 문제
- 스키마 정의를 통한 계약 정의
GraphQL Schema#
The Schema Definition Language(SDL)
- GraphQL은
Schema사용하여 API의 기능을 정의 - API에 노출되는 모든 유형은 GraphQL SDL (스키마 정의 언어)을 사용하여
Schema에 기록됨
스키마는 클라이언트가 데이터에 액세스 할 수 있는 방법을 정의하며 클라이언트와 서버 간의 계약 역할을 수행
Schema 정의#
- 프런트엔드와 백엔드에서 작업하는 팀은 네트워크를 통해 전송되는 데이터의 명확한 구조를 알고 있기 때문에 추가 통신없이 작업을 수행 가능
- 프런트 엔드 팀은 필요한 데이터 구조를 모의하여 애플리케이션을 쉽게 테스트 가능
- 서버가 준비되면 클라이언트 앱이 실제 API에서 데이터를 로드하고 제어할 수 있음
다음은 SDL을 사용하여 다음과 같은 간단한 유형을 정의해보자#
Person 스키마 인물 정보
Tip 필수로 입력되야 한다면 "!" 사용
Post 스키마 게시물 정보
Person Post 일대 다 관계
GraphQL Query#
REST API로 작업 할 때 데이터는 특정 엔드 포인트에서 로드하지만..
기관 목록 요청#
특정 기관 요청#
- GraphQL에서 취하는 접근 방식은 근본적으로 다름
- REST에서는 고정 데이터 구조를 반환하는 여러 엔드 포인트를 갖는 대신 GraphQL API는 일반적으로 단일 엔드 포인트 만 노출하여 사용
- 이는 반환되는 데이터의 구조가 고정되지 않았기 때문에 작동하며, 대신 완전히 유연하게 클라이언트가 실제로 필요한 데이터를 결정할 수 있음
GraphQL에서 클라이언트는 데이터 요구 사항을 표현하기 위해 서버에 더 많은 정보를 보내야 한다. 이 정보를
Query라고 한다.
여기서 allPersons 은 Query의 루트 필드
루트 필드 뒤에 오는것은 모두 PayLoad가 된다.
현재는 name만 지정해줬으니 name 필드만 가져오는 Payload가 되겠다.
응답 예시#
사용자의 이름, 나이까지 가져오는 Query#
사용자 이름, 나이 + 사용자의 모든 게시물의 제목을 포함하여 가져오는 Query#
인수가있는 쿼리(특정 사람수만 반환)#
여태 작성한 스키마들은 단순히 GraphQL 유형의 모음
GraqhQL 미리 타입과 유형에 대한 스키마 정의를 하고 API에 대한 스키마를 작성시 몇가지 특별한 루트 유형을 제공한다.
지금까지는 query 키워드와 query 이름을 모두 생략 한 단축 문법을 사용했지만, 실제 애플리케이션에서는 코드를 덜 헷갈리게 작성하는 것이 좋다. GraphQL Learn 문서
graphql Query 요청#
사용자 목록 Query 작성
인수 포함한 Query 작성
2021-03-16#
List#
- GraphQL
- mutation
- subscription
- resolver
mutation#
서버에서 정보를 요청하는 것 외에도 대부분의 애플리케이션은 현재 백엔드에 저장된 데이터를 변경할 수 있는 방법이 필요하다.
GraphQL 에서는 변경에 대해 mutation을 사용한다.
- 새로운 데이터 생성
- 기존 데이터 업데이트
- 기존 데이터 삭제
Person Create mutation#
여기서 createPerson은 mutation의 루트 필드
이전에 작성한 쿼리와 유사하게 변이에도 루트 필드 가 있다. 이 경우 createPerson 필드는 새로운 사용자의 name, age 두 개의 인수를 사용하여 Create 한다.
mutation은query와 동일한 구문 구조를 따르지만 항상 mutation 키워드로 시작해야 한다.
위에서 query처럼 mutation에 대한 payload를 지정할 수도 있다.
mutation을 보낼 때 정보를 쿼리 할 수도 있다는 것은 단일 왕복으로 서버에서 새로운 정보를 검색 할 수있는 매우 강력한 도구가 될 수 있다.
응답 예시#
Useful Pattern#
자주 발견되는 패턴 중 하나는 GraphQL 유형에 새 개체가 생성 될 때 서버에서 생성되는 고유 ID가 존재한다.
예시로 Person 이전에서 유형을 확장 하면 다음과 같이 추가 할 수 있다.
mutation createPerson (return id)#
새로운 Person이 생성 될 때 클라이언트에서 미리 사용할 수 없었던 새로 생성되는 ID를 페이로드에 요청하여 사용이 가능
subscription#
오늘날 많은 응용 프로그램에 대한 또 다른 중요한 요구 사항 은 중요한 이벤트에 대한 즉각적인 정보를 얻기 위해 서버에 실시간으로 연결하는 것이 있다. 이 사용 사례를 위해 GraphQL은 subscription 개념을 제공한다.
- 클라이언트에서 subscription 이벤트에 의해 서버에 대한 안정적인 연결을 시작하고 유지
- 특정 subscription 이벤트가 실제로 발생할 때마다 서버는 해당 데이터를 클라이언트에 푸시
- 일반적인 "요청-응답 주기" 를 따르는
query및mutation과 달리subscription은 클라이언트로 전송되는 데이터 스트림 을 나타냄
subscription newPerson#
- 클라이언트에서 subscription을 서버로 보낸 후 이들간에 연결이 Open
- person을 생성하는 새로운
mutation이 수행 될 때마다 서버는 person에 대한 정보를 클라이언트로 Send
모든 스키마#
resolver#
graphql 에서는 데이터를 가져오는 구체적인 과정을 직접 구현 해야 한다.
- graphql에서 쿼리문 파싱은 대부분의 gql 라이브러리에서 처리를 지원
- graphql에서 데이터를 가져오는 구체적인 과정은
resolver가 담당하고, 이를 직접 구현 해야함
프로그래머는 리졸버를 직접 구현해야하는 부담은 있지만, 이를 통해서 데이터 소스의 종류에 상관 없이 구현이 가능 한 이점이 있다.
이점의 예시#
- 리졸버를 통해 데이터를 데이터베이스에서 가져온다
- 일반 파일에서 데이터를 가져온다.
- HTTP, SOAP, REST 와 같은 네트워크 프로토콜을 활용해서 원격 데이터를 가져온다.
- legacy 시스템을 gql 기반으로 바꾸는데 활용 할 수 있다.
2021-03-30#
List#
- GraphQL
- Architecture
Use Cases#
GraphQL 서버를 포함하는 3가지 다른 종류의 아키텍처에 예시를 들어본다.
- 연결된 데이터베이스가있는 GraphQL 서버
- 기존 A 시스템을 GraphQL 서버로 타사의 혹은 기존 시스템과 통합하고 이를 단일 GraphQL API를 구성
- 동일한 GraphQL API를 통해 모두 액세스 할 수 있는 연결된 데이터베이스와 타사 또는 레거시 시스템의 하이브리드 접근 방식
연결된 데이터베이스가있는 GraphQL 서버#
이 아키텍처는 여러 프로젝트 에서 가장 일반적이다.
- 설정에는 GraphQL 사양을 구현하는 단일 (웹) 서버가 존재
- 쿼리가 GraphQL 서버에 도착하면 서버는 쿼리의 페이로드를 읽고 데이터베이스에서 필요한 정보를 가져옴 ->
resolving the query - 응답 객체를 구성 하고 클라이언트에 반환
GraphQL은 실제로 전송 계층에 구애받지 않는다는 점에 유의해야하며 이것은 잠재적으로 사용 가능한 네트워크 프로토콜과 함께 사용할 수 있음
따라서 TCP, WebSockets 등을 기반으로 GraphQL 서버를 구현하는 것이 잠재적으로 가능합니다.
GraphQL은 또한 데이터베이스 나 데이터를 저장하는 데 사용되는 형식에 대해 신경 쓰지 않는다. AWS Aurora 와 같은 SQL 데이터베이스 또는 MongoDB 와 같은 NoSQL 데이터베이스를 사용할 수 있습니다.
단일 데이터베이스에 연결되는 하나의 GraphQL 서버가 있는 표준 아키텍처

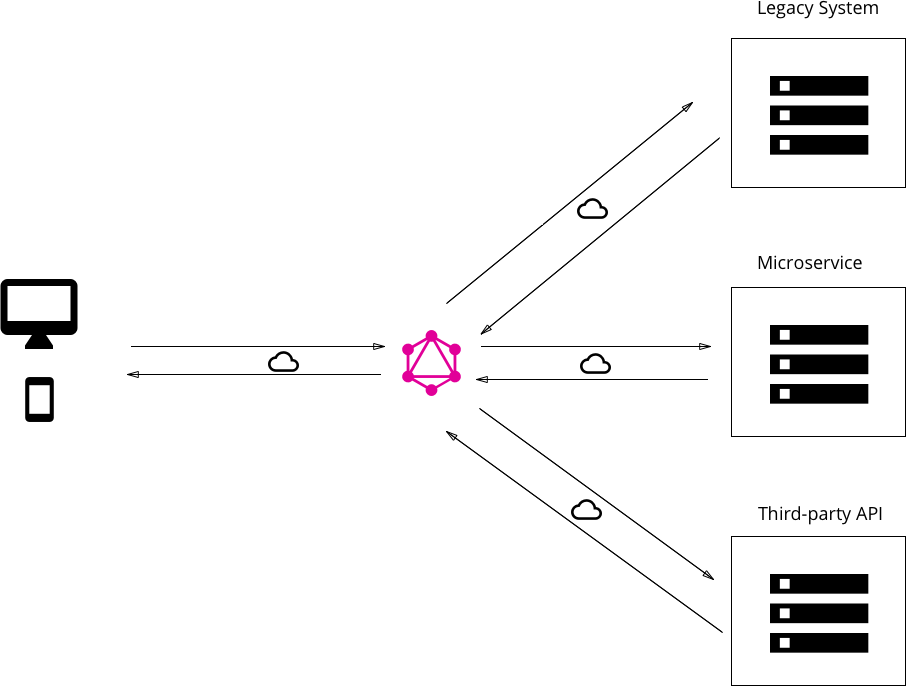
기존 시스템을 통합하는 GraphQL 계층#
일관된 단일 GraphQL API 뒤에 여러 기존 시스템을 통합하는 케이스.
레거시 인프라와 수년에 걸쳐 성장하여 현재 높은 유지 관리 부담을 부과하는 다양한 API를 보유한 상황에 적합
- 레거시 시스템의 한 가지 주요 문제는 여러 시스템에 액세스해야하는 혁신적인 제품을 구축하는 것이 사실상 불가능
- GraphQL은 이러한 기존 시스템 을 통합 하고 GraphQL API 뒤에 복잡성을 숨기는 데 사용할 수 있음
- GraphQL 서버와 통신하여 필요한 데이터를 가져 오는 새로운 클라이언트 애플리케이션을 개발가능
위에 조건들을 만족하여 GraphQL 서버는 기존 시스템에서 데이터를 가져와 GraphQL 응답 형식으로 패키징하여 사용할 수 있다.
GraphQL 서버가 사용중인 데이터베이스 유형에 이전 아키텍처와 마찬가지로
Query를 해결하는데 필요한 데이터를 가져올 때 데이터 소스, 코드, 환경에 대해서는 관심이 없어도 된다.
GraphQL을 사용하면 단일 GraphQL 인터페이스 뒤에있는 마이크로 서비스, 레거시 인프라 또는 타사 API와 같은 기존 시스템의 복잡성을 숨김
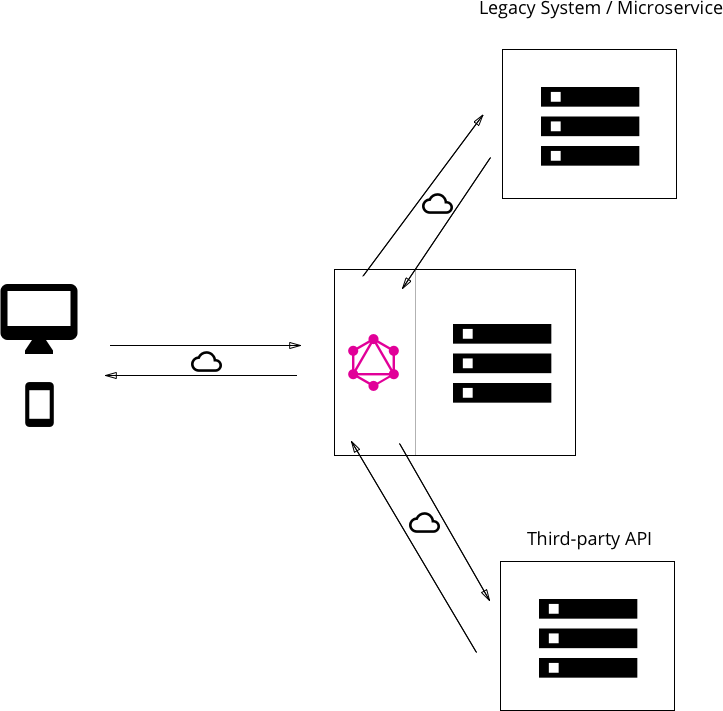
연결된 데이터베이스와 기존 시스템의 통합을 통한 하이브리드 접근#
두 가지 접근 방식을 결합하여 연결된 데이터베이스가 있지만 여전히 레거시 또는 타사 시스템과 통신하는 GraphQL 서버를 구축 할 수 있는 케이스
서버가
Query를 수신하면Query를 해결하고 연결된 데이터베이스 또는 일부 통합 API에서 필요한 데이터를 검색
GraphQL 서버는 기존 시스템뿐 아니라 단일 데이터베이스에서 데이터를 가져올 수 있으므로 완전한 유연성을 제공하고 모든 데이터 관리 복잡성을 서버로 보낼 수 있음
Resolver 기능#
- GraphQL을 통해 이러한 유연성을 어떻게 얻을 수 있을까?
- 이처럼 매우 다른 종류의 사용 사례에 얼마나 적합할까?
GraphQL은 Query (또는 Mutation)의 Payload는 필드 집합으로 구성 된다. GraphQL 서버 구현에서 이러한 각 필드는 실제로 resolver 라는 정확히 하나의 함수에 해당 된다.
리졸버 함수의 유일한 목적은 해당 필드에 대한 데이터를 가져 오는 것입니다.
- 서버가
Query를 수신하면Query의Payload에 지정된 필드에 대한 모든 함수를 호출 Resolves the Query각 필드에 대한 올바른 데이터를 검색- 모든
Resolver가 반환되면 서버는Query에서 설명한 형식으로 데이터를 패키징하여 클라이언트로 다시 보냄
위에 방식등을 통해 유연하게 데이터를 패키징할 수 있음
Resolver 필드 이름 중 일부가 포함되어 있는 상황에서 Query의 각 필드는 Resolver Function에 해당 된다. GraphQL은 지정된 데이터를 가져 오기 위해 Query가 들어올 때 필요한 모든 Resolver를 호출합니다.
